简单爬虫的编程实现
学习笔记 | 📅 2020-11-25 | spider
我们使用Python实现一个简单的爬虫,但并不表示只能用Python实现,逻辑和思路是通用的,任何语言实现都没有问题。
基本思路
根据爬虫的核心功能:
- 首先,爬虫应有初始的URL,作为爬取的起点
- 其次爬虫应当能够下载URL指定的资源
- 爬虫需要处理下载的资源,从中提取所需的数据或者信息
- 爬虫应该能从下载的资源中发现新的资源对应的URL
我们定义如下模块:
- 初始化模块,接受参数产生初始URL
- 下载器,用于下载URL指定的资源
- 解析器,用于解析下载到的资源内容并发现新的URL
- 调度器,用于管理下载器和解析器,控制数据流向
模块实现
我们通过简单的代码实现上述内容:
下载器
def downloader(url:str) -> str:
"""
下载器
"""
try:
# 请求URL并返回内容
resp = requests.get(url=url)
return resp.text
except :
return ""
这个下载器,使用 requests 库,对URL标识的资源进行下载,并返回文本内容。如果出错则返回空字符串。
解析器
def resolver(content:str) -> [str]:
"""
解析器
"""
# 定义正则
pattern = re.compile('http(s)?://[A-Z0-9a-z.]+')
result = []
# 提取URL
for item in pattern.finditer(content):
result.append(item.group())
return result
这个解析器,使用 re 库,通过正则表达式,从文本内容中提取文本内的URL信息。并将找到的URL组织成 list 返回。
调度器
def scheduler(start_url:str):
"""
调度器
"""
url_list = []
cur_url = start_url
while True:
content = downloader(cur_url)
urls = resolver(content)
url_list.extend(urls)
print(f"从 {cur_url} 找到 {len(urls)} 个 URL。")
cur_url = url_list.pop()
这个调度器,以参数传入的URL为起点,分别调用“下载器”和“解析器”获得URL数据,并存储于 url_list 内。输出从当前URL获得的新URL数量。
调用逻辑
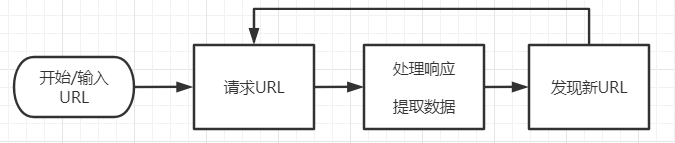
核心逻辑是 “调度器” 内的循环,基本实现了上图的处理流程。它将“请求”、“处理”、“发现”三个步骤联合起来,完成了爬虫在网络中到处“爬行”的功能。
代码展示
import re
import requests
def downloader(url:str) -> str:
"""
下载器
"""
try:
# 请求URL并返回内容
resp = requests.get(url=url)
return resp.text
except :
return ""
def resolver(content:str) -> [str]:
"""
解析器
"""
# 定义正则
pattern = re.compile('http(s)?://[A-Z0-9a-z.]+')
result = []
# 提取URL
for item in pattern.finditer(content):
result.append(item.group())
return result
def scheduler(start_url:str):
"""
调度器
"""
url_list = []
cur_url = start_url
while True:
content = downloader(cur_url)
urls = resolver(content)
url_list.extend(urls)
print(f"从 {cur_url} 找到 {len(urls)} 个 URL。")
cur_url = url_list.pop()
if __name__ == "__main__":
scheduler("https://baidu.com")