网络爬虫简介
学习笔记 | 📅 2020-11-24 | spider
网络爬虫是什么
根据一般定义:
网络爬虫,是一种按照一定规则,自动地浏览万维网信息地程序或者脚本。
由上述定义可知,网络爬虫是一种程序或者脚本,用于自动化地访问万维网地信息。提取关键信息可知网络爬虫地特性为:
- 能按规则访问万维网
- 能获取万维网的信息
- 能自动化地执行
- 本体是一个程序或者脚本
网络爬虫的运行基础
HTTP协议
超文本传输协议,是万维网的数据通信的基础。爬虫可以基于此协议,通过统一资源标识符(URL)来获取万维网上的信息。
HTTP协议有两个特点,能够被爬虫利用:
- 超文本资源与URL一一对应,方便检索
- 超文本资源本身是文本信息,容易处理
正是基于上述两点,爬虫才能更容易地、准确快速地获取信息。
万维网
“万维网”是一个由许多超文本互相链接组成的系统。由于其“互相链接”的特性,我们可以通过一个 URL 标识的资源找到另一个(或者多个)资源。
“万维网”中的超文本通过互相链接,组成了一个网状结构。而网络爬虫,能通过一个资源寻找到另一个资源,并循环下去。就如同一个爬虫在“万维网”的网状结构中穿行,这也是“爬虫”名称的由来。
网络爬虫的基本结构
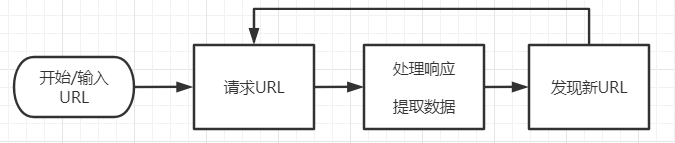
基于上图,一个简单的爬虫,应该具有下述四点核心功能:
- 首先,爬虫应有初始的URL,作为爬取的起点
- 其次爬虫应当能够下载URL指定的资源
- 爬虫需要处理下载的资源,从中提取所需的数据或者信息
- 爬虫应该能从下载的资源中发现新的资源对应的URL
爬虫无论如何优化,都是为了更好地执行上述四个功能。后续地优化,也都将以这四个功能为基础。